Process
I began by delving into the Decision Tree classifier, comparing different parameter combinations such as Gini index vs. Entropy, along with max_depth and min_samples_leaf, to ascertain the optimal setup through cross-validation.
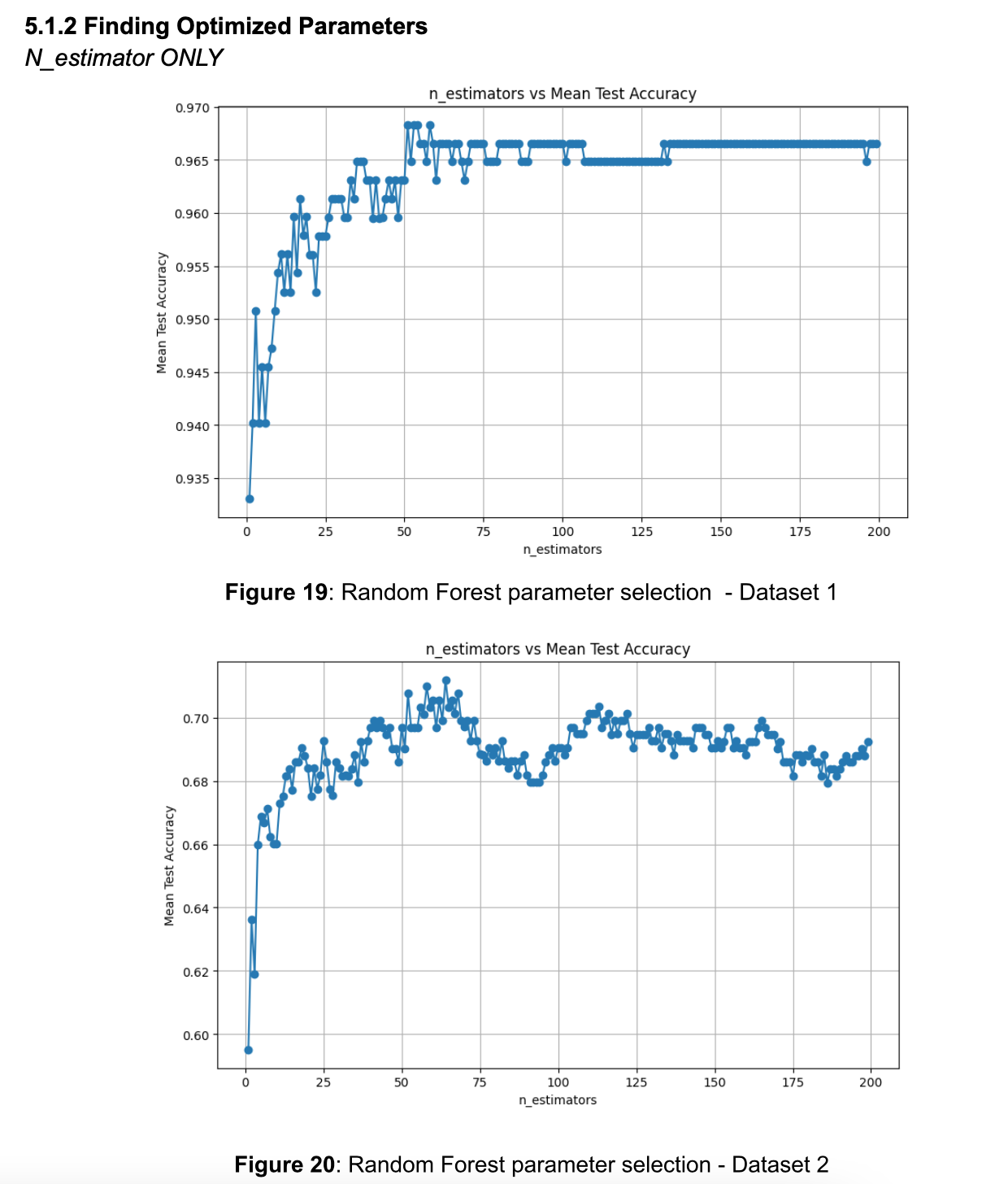
Building on this, I expanded my exploration to the Random Forest classifier, analyzing the effects of n_estimators and max_depth on model performance.
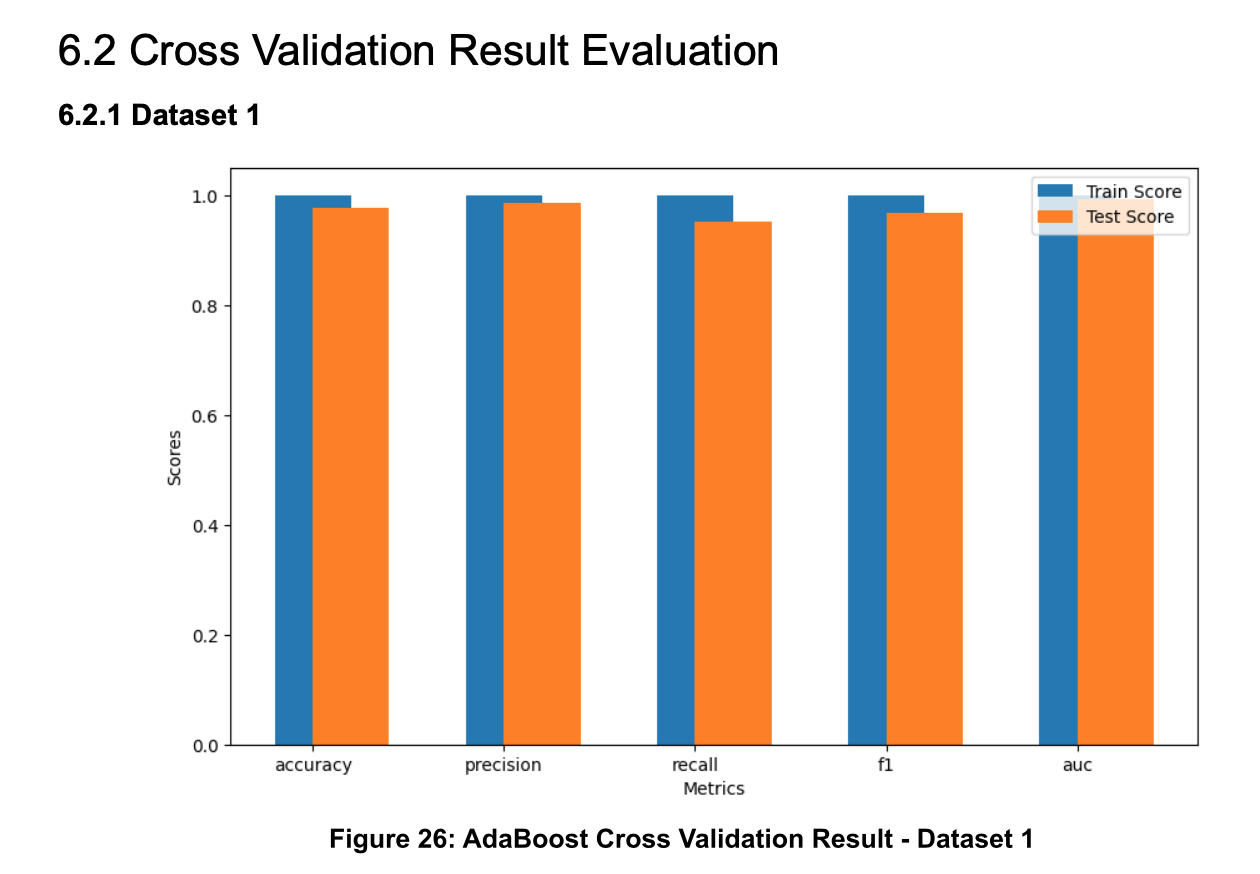
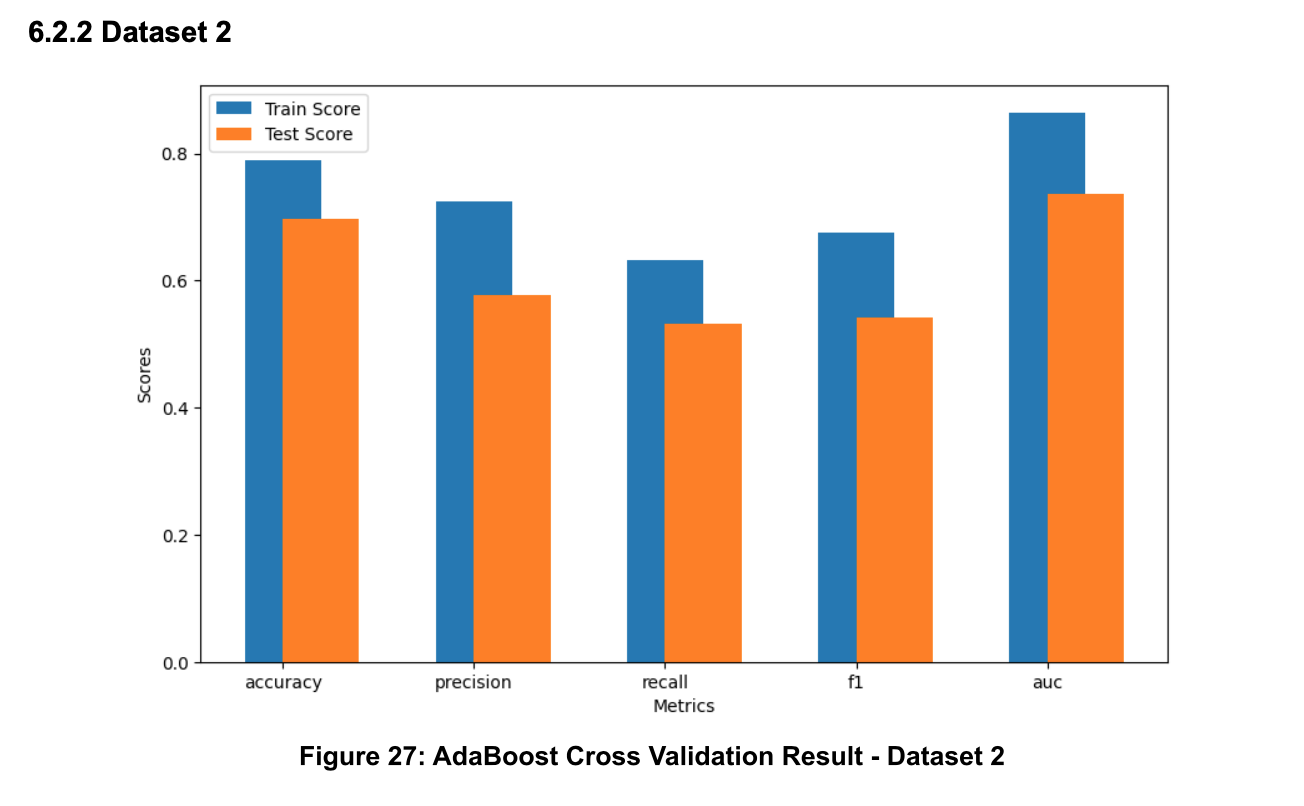
The evaluation of classifier performance was comprehensive, based on a 10-fold Cross Validation in terms of accuracy, precision, recall, F1 score, and AUC to ensure a holistic understanding of each model's strengths and weaknesses.
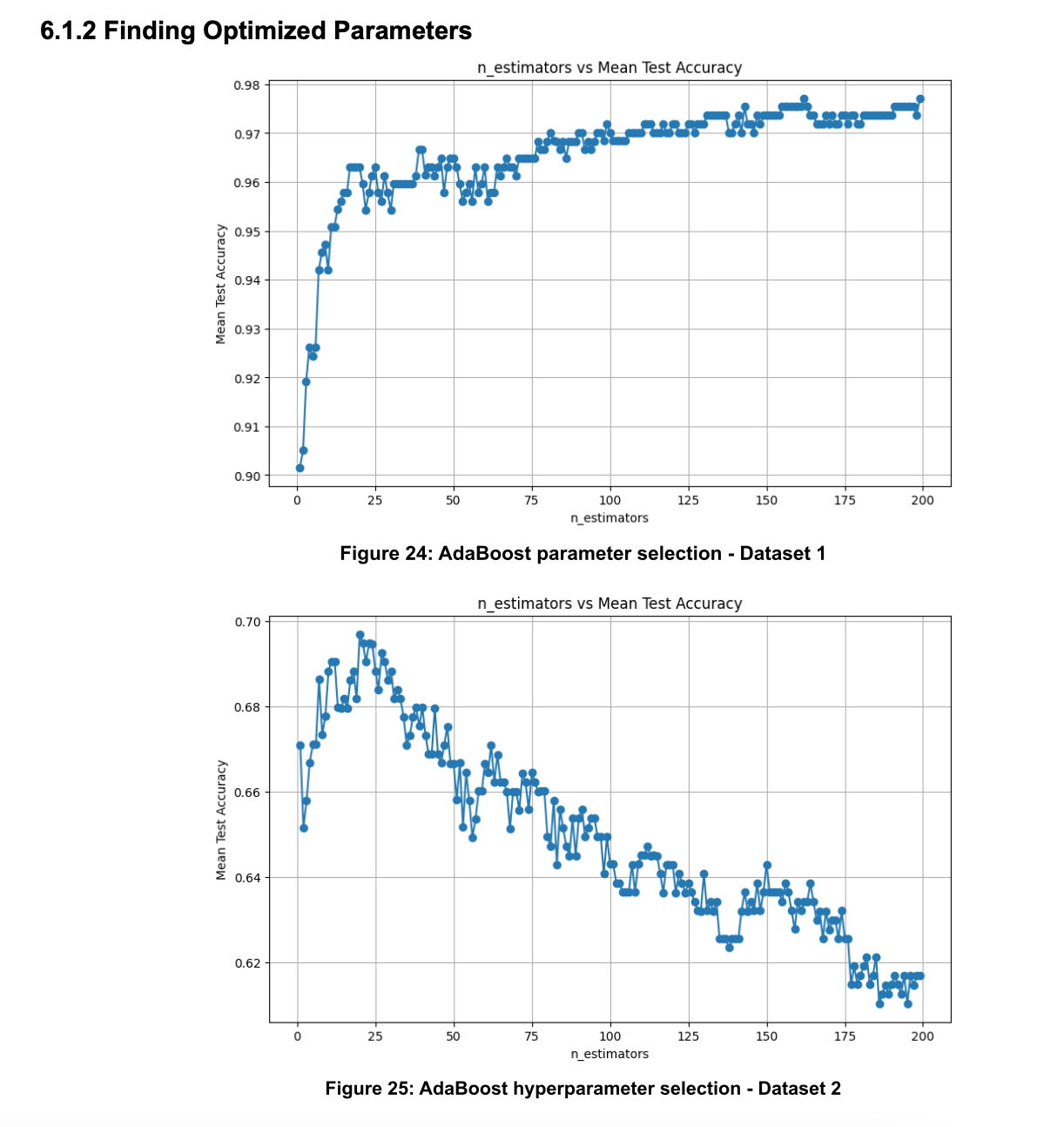
Moreover, I experimented with AdaBoost, a technique known for its ability to integrate multiple weak learners into a formidable ensemble model. This approach was particularly intriguing due to its inherent resistance to overfitting, a challenge I noted in both Decision Tree and Random Forest models under certain conditions.